Ein Kunde gibt „rotes Kleid" in Ihre Suchleiste ein und erhält neun Ergebnisse. Sie haben einundvierzig rote Kleider auf Lager. Die anderen zweiunddreißig sind als „karminrot", „bordeaux", „rubinrot", „weinrot" getaggt, und eines hat ein Lieferant als „RD-447 / kirschton / FINAL" hochgeladen. Sie tauchen nie auf. Der Kunde nimmt an, dass Sie nicht führen, was er sucht, und verlässt den Shop.
Das ist kein Suchproblem. Es ist ein Datenproblem im Gewand eines Suchproblems. Und es ist derselbe Grund, aus dem ein Kunde ein Kameraobjektiv kauft, das nicht auf sein Bajonett passt, ein 110-V-Gerät für ein 220-V-Land bestellt oder eine „spritzwassergeschützte" Uhr zurücksendet, nachdem er sie im Schwimmbad getragen hat. Ihre Produktseiten enthalten die Antwort irgendwo. Sie enthalten sie nur nicht in einer Form, die irgendetwas verarbeiten kann.
Ihr Katalog ist voller Text, aber leer an Bedeutung
Die meisten Kataloge wurden gebaut, um eine Seite darzustellen, nicht um eine Frage zu beantworten. Ein Produkt hat einen Titel, einen Marketingtext, vielleicht eine Aufzählungsliste, einen Preis und ein Foto. Für einen Menschen, der einen Artikel nach dem anderen liest, reicht das. Für ein System, das versucht, vierzig Artikel zu vergleichen oder ein passendes Zusatzprodukt zu empfehlen, ist es fast nichts.
Hier ist der Grund. „Strapazierfähiges Baumwoll-Mix-Shirt, ideal für den Sommer" liest sich gut. Aber Ihre Filter wissen nicht, dass das Material ein Baumwollgemisch ist, dass es ein sommerleichter Artikel ist oder dass „strapazierfähig" eine Behauptung und keine Messgröße ist. Drei Lieferanten schreiben dieselbe Spannung als „110v", „110 Volt" und „110 V" — und ein Filter behandelt das als drei verschiedene Dinge oder ignoriert sie alle. Der Text, der sagt, ein Objektiv „passt auf die meisten Standard-Bajonette", ist schlimmer als nutzlos: Er klingt beruhigend und sagt dem Käufer nichts darüber, ob es auf sein Gehäuse passt.
Das ist die Lücke, die eine Produktintelligenz-Plattform schließen soll. Nicht, indem sie bessere Werbetexte schreibt, sondern indem sie die Texte, die Sie bereits haben, in strukturierte Fakten verwandelt, die eine Maschine sortieren, filtern, vergleichen und über die sie schlussfolgern kann. Eine oberflächliche Produktseite wird zu einer Reihe entscheidungsreifer Attribute. Diese Verschiebung ist das ganze Spiel.
Anreicherung: Aus Prosa werden Fakten
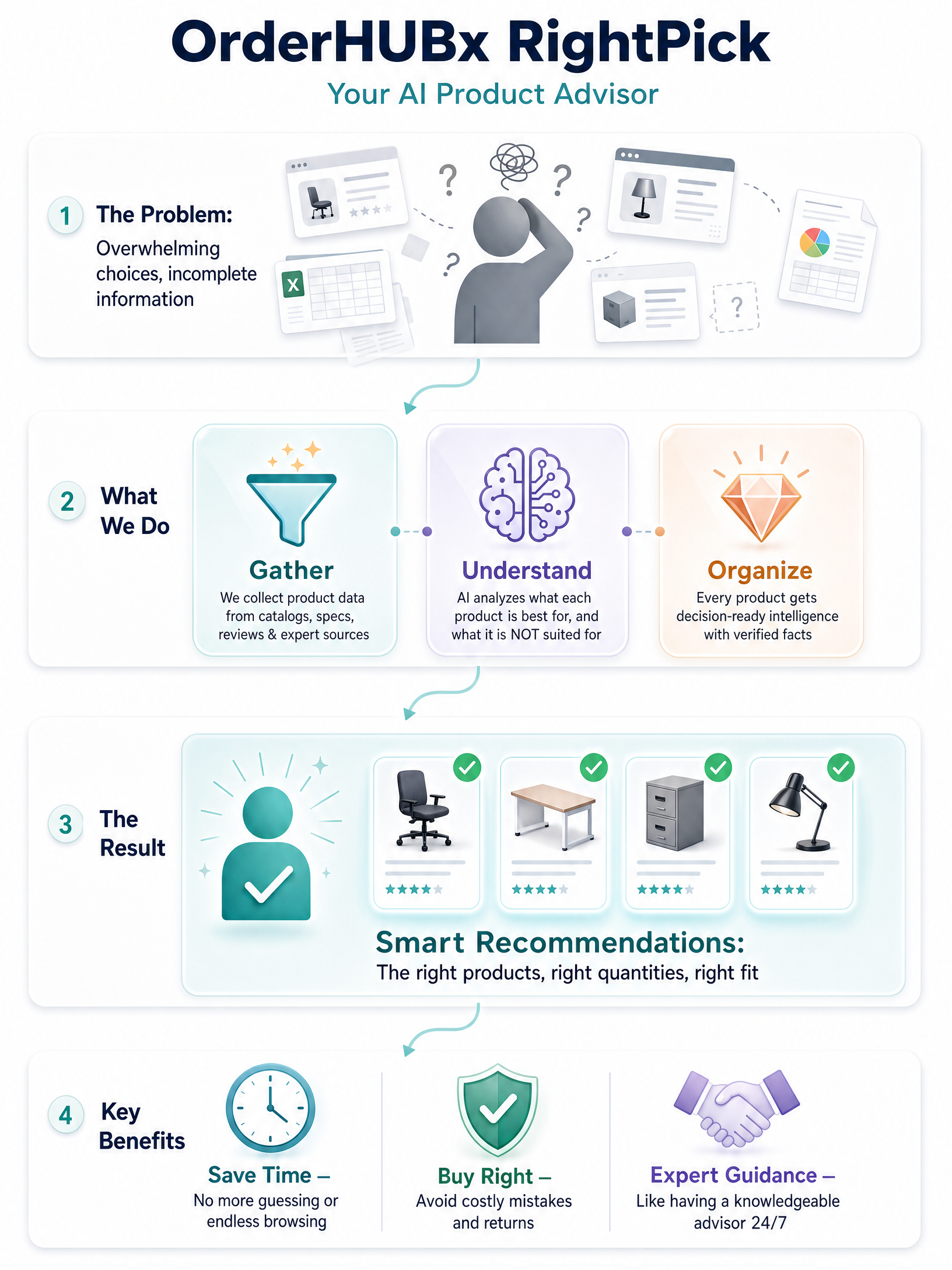
Die erste Aufgabe ist die E-Commerce-Produktdaten-Anreicherung — die Bedeutung aus dem Durcheinander herauszuholen. Modelle lesen Ihre Titel, Beschreibungen, Aufzählungspunkte, Datenblätter, Lieferanten-Feeds und sogar die Produktfotos und extrahieren Attribute, mit denen Sie tatsächlich arbeiten können. Material, Farbfamilie, Maße, Gewicht, Spannung, Kapazität, Passform, Einsatzzweck. Die Dinge, die ein Kunde einen sachkundigen Verkäufer fragen würde, wenn einer danebenstünde.
Sie tut vier Dinge, ungefähr in dieser Reihenfolge. Sie extrahiert Attribute, die in der Prosa vergraben waren. Sie standardisiert sie, sodass „karminrot", „rubinrot" und „weinrot" alle zu einer roten Farbfamilie zusammenlaufen und „110v" und „110 Volt" zu einem Wert werden. Sie ergänzt Kompatibilität — welches Objektiv auf welches Gehäuse passt, welcher Akku welches Gerät betreibt, welche Nachfüllung zu welchem Spender passt. Und sie ergänzt Kontext, den Teil, den Menschen tatsächlich zur Entscheidung nutzen: „spritzwassergeschützt" ist ehrlich, aber „gut für Regen und Spritzer, nicht zum Schwimmen" ist das, was die Rücksendung verhindert.
| Was die Anreicherung tut | Was jetzt auf der Seite steht | Was das System bekommt |
|---|---|---|
| Attribute extrahieren | „Strapazierfähiges Baumwoll-Mix-Shirt, ideal für den Sommer." | Material: Baumwollgemisch · Saison: Sommer · Gewicht: leicht |
| Werte standardisieren | „110v", „110 Volt", „110 V" | Spannung: 110V (ein einziger kanonischer Wert) |
| Kompatibilität ergänzen | „Passt auf die meisten Standard-Bajonette." | Passt auf Bajonett A, Bajonett B; nicht auf Bajonett C |
| Kontext ergänzen | „Spritzwassergeschützt." | Gut für Regen und Spritzer; nicht zum Untertauchen |
Nichts davon ist glamouröse Arbeit. Es ist die digitale Version eines Lagermitarbeiters, der jeden Artikel in der Hand gehabt hat und Ihnen ohne nachzusehen sagen kann, dass das blaue Modell kleiner ausfällt und das billigere Ladegerät Ihr Handy nicht schnell lädt. Die Anreicherung füllt dieses Wissen in Flaschen und wendet es auf jede SKU an — auch auf die vierhundert, die Sie vor zwei Jahren in aller Eile hochgeladen und nie wieder angefasst haben.
Warum ein Wissensgraph und nicht einfach mehr Spalten
Sie könnten bei der Anreicherung aufhören, alles in eine Tabelle mit hundert Spalten kippen und Feierabend machen. Viele Teams tun genau das. Das Problem ist, dass eine flache Tabelle Fakten speichern, sie aber nicht verbinden kann. Sie weiß, dass ein Objektiv das Attribut „E-Mount" hat und ein Kameragehäuse das Attribut „E-Mount" hat. Sie weiß nicht, dass diese beiden Fakten bedeuten, dass das Objektiv auf das Gehäuse passt.
Ein Produkt-Wissensgraph speichert die Verbindungen, nicht nur die Werte. Produkte, Attribute, Kategorien, Marken und Einsatzzwecke werden zu Knoten; die Beziehungen zwischen ihnen — passt auf, benötigt, ersetzt, kombiniert mit, ist eine Art von — werden zu den Verbindungen. Sobald diese Verbindungen bestehen, kann das System schlussfolgern, statt nur abzugleichen.
Nehmen Sie einen Kunden, der „Campingausrüstung für kaltes Wetter" sucht. Eine Stichwortsuche fahndet nach den wörtlichen Begriffen „kaltes Wetter" in Ihrem Text und übersieht einen Schlafsack mit einer Eignung bis −9 °C, weil niemand „kaltes Wetter" in seine Beschreibung geschrieben hat. Ein Graph weiß, dass eine Eignung bis −9 °C tatsächlich kältetauglich ist, dass Daunenfüllung zum selben Einsatzzweck gehört und dass jemand, der diesen Schlafsack kauft, wahrscheinlich auch eine isolierte Unterlage haben möchte — weil der Graph gesehen hat, wie diese Knoten zusammenhängen. Das ist der Unterschied zwischen einem Katalog, der Produkte auflistet, und einem, der sie versteht. Es ist auch das, was echte semantische Suche möglich macht: Das System beantwortet die Frage hinter den Worten, nicht die Worte.
Was das tatsächlich behebt
Konkret werden drei Dinge besser, und es sind die drei, die Sie Geld kosten.
Die Suche findet, was Sie verkaufen. Wenn Farbfamilien, Materialien und Einsatzzwecke standardisiert sind, sieht der Kunde, der ein rotes Kleid sucht, alle einundvierzig — nicht neun. Weniger Sackgassen-Suchen bedeuten weniger Menschen, die annehmen, Sie seien ausverkauft, und gehen.
Rücksendungen sinken. Die meisten Rücksendungen wegen falscher Passform lassen sich auf einen Fakt zurückführen, der auf der Seite stand, aber unbrauchbar war — das Bajonett, das nicht passte, die Spannung, die niemand markiert hat, die „spritzwassergeschützte" Uhr, die nicht wasserdicht war. Kompatibilitäts- und Kontextattribute fangen das ab, bevor die Bestellung versandt wird, nicht erst nach der wütenden E-Mail.
Empfehlungen hören auf zu raten. „Kunden kauften auch" ist Beliebtheit, nicht Relevanz. Ein Graph kann das Ladegerät empfehlen, das tatsächlich zum Handy passt, den Filter, der zur Kamera passt, die Nachfüllung, die zum Spender passt — weil er die Beziehung kennt, nicht nur das Mitkauf-Muster. Das ist der Unterschied zwischen einem Upselling, das Menschen nervt, und einem, das ihnen hilft.
Wo Sie anfangen sollten
Sie müssen nicht am ersten Tag hunderttausend SKUs anreichern. Fangen Sie dort an, wo der Schmerz am lautesten ist. Ziehen Sie Ihre dreißig häufigsten Suchbegriffe heran, die weniger als eine Handvoll Ergebnisse liefern, und prüfen Sie, ob der Bestand unter einem anderen Namen existiert — das zeigt Ihnen, wie viel Ihre Suche verbirgt. Ziehen Sie Ihre SKUs mit den höchsten Rücksendequoten heran und lesen Sie die Produktseite so, als wären Sie der Kunde, der sie zurückgeschickt hat. In neun von zehn Fällen war der Fakt, der die Rücksendung verhindert hätte, fehlend, vage oder vergraben.
Beheben Sie diese zuerst. Standardisieren Sie die Attribute, die Ihre meistgenutzten Filter antreiben, ergänzen Sie Kompatibilität in den Kategorien, in denen Käufer danebenliegen, und schreiben Sie die Kontextzeilen, die Ihren häufigen Rücksendungen zuvorkommen. Allein das bewegt die Zahlen. Der Wissensgraph ist das, was die Verbesserung kumulieren lässt, weil sich jedes neue Produkt in eine Struktur einfügt, die bereits weiß, wie die Dinge zusammenhängen.
Das ist das Problem, für das OrderHUBx RightPick gebaut ist — verstreute Katalogdaten in strukturierte Attribute anzureichern und sie in einem Graphen zu verbinden, damit das System die richtigen Produkte in den richtigen Mengen empfehlen kann, mit der Begründung, die das untermauert. Es befindet sich gerade im Early Access, also werden wir keine Kundenzahlen herumschwenken, die wir uns noch nicht verdient haben. Aber der Ansatz ist der oben beschriebene, durchgängig angewendet statt SKU für SKU.
Die ehrliche Zusammenfassung lautet: Ihre Produktseiten wurden geschrieben, um von Menschen gelesen zu werden, einzeln. In dem Moment, in dem Software den gesamten Katalog durchsuchen, vergleichen, empfehlen oder über ihn schlussfolgern soll, reicht „zum Lesen geschrieben" nicht mehr aus. Die Anreicherung verwandelt die Prosa in Fakten. Ein Graph verwandelt die Fakten in Verständnis. Und Verständnis ist das, was eine Browsing-Sitzung in eine Kaufentscheidung verwandelt.